Out of Sorts, take 3
Having, erm, sorted out book list sorting back in January 1989 (on my Amstrad CP/M PC), and, a year later book list sorting (under Acorn RISC OS), how about some really modern book list sorting, undertaken with the help of a SQLite DB and some adroit Python snake charming? On a 64-bit Linux Mint 17.2 system?
Funnily enough...
... I recently found the book by Margaret Visser I mentioned last time. But that's a different story.
During recent walks, I've been teased by Brian for my Luddite approach to data file handling. He maintains it can always be done better using Python. "It" being text field handling... basically. For the last umpty1 years I've been keeping simple ASCII data files of my books, videos, and music. Until 1994, I would occasionally print these out as jolly nice DTP catalogues that the print room staff in the basement of IBM Hursley house were happy to copy, collate, and bind for me in return for small-scale financial inducements. Or even just a few good jokes, leavened with some of my more scandalous gossip.
What happened in 1994? Basically, the web.
By the time it arrived, I was actually well-prepared for it. (And delighted by the way the IBM Lab adopted it so quickly.) The books I'd been writing in IBM (well, the official ones, at least) for a decade or so had all used a variant markup language, so HTML seemed like just another set of tags to handle. With less paper2 to be printed.
Having seen the ease and usefulness of HTML and web pages, my book lists have lived on in cyberspace. With the invaluable assistance of the block and column manipulation facilities of the excellent TextPad editor on Windows I would sort them by Author, by Title, by Genre, by price, by date of purchase... and then lazily whack them in between a pair of <pre> and </pre> tags, with a bit of HTML / CSS wrappering, and just let the user's web browser page rendering engine do all the hard work. Tab-separated data. What could be easier?
"Why do it that way?" asks Brian, visibly offended and horrified at the thought of treating data in such a haphazard, cavalier way. (He was too polite to say "amateurish", but I've known him long enough to know that's what he was thinking. And he's right.) "Show me a better way", says I. He very soon did.
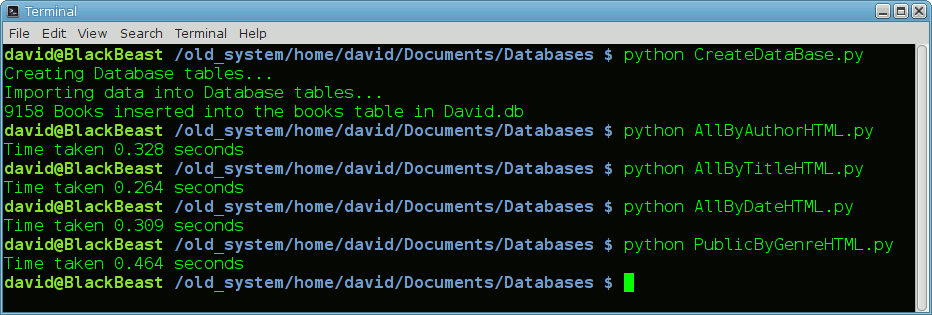
That's why I'm now the proud owner of a 9,000+ entries SQLite DB stuffed full of properly organised books data fields. And a matching set of five Python query programs to extract the data (which SQLite will kindly sort in any order, or set of orders, desired, when in the act of extracting what's been requested and handing it over to Python). Python then formats it neatly (with some CSS assistance from me), looks after all the special cases introduced by authors whose names contain accents, or who insist on a surname beginning with a lowercase3 letter, or book titles similarly afflicted. At the end of all this data mangling, of course, the finished web page files are indistinguishable from the hand-crafted horrors I've been laboriously producing at fairly regular intervals for the last couple of decades.
However, there is one crucial difference.
On my quad core i7 BlackBeast PC all five generated web lists are produced — ready for uploading straight on to my web server(s) — in less than two seconds of CPU time. And perhaps 30 or 40 seconds of total typing time at a terminal prompt. Now, even given my reasonable level of skill with TextPad it could easily take me a couple of hours to prepare one of these files manually on Windows. (Mind you, I still remember the first time I successfully sorted and merged4 my books database on CP/M, too, using Mallard BASIC. It took over 20 minutes to chew its way through just over 5,000 records. Let's not even think about how long the subsequent noisy impact printing would then take, too.)
The five Python programs are:
1. CreateDataBase.py — to populate the SQLite DB "David.db" with the contents of the NewBooksMaster.txt ASCII file
2. AllByAuthorHTML.py — to create the (internal) All Authors SHTML listing
3. AllByTitleHTML.py — to create the (internal) All Titles SHTML listing
4. AllByDateHTML.py — to create the (internal) All by purchase date SHTML listing
5. PublicByGenreHTML.py — to create the two (public) SHTML listings, subsorted by genre
See how they run!
A recent example, run on 9th May, 2016: